Last week I have realized that I had a blind spot: I thought that every developer is aware that selling software or delivering a product are not quite the same. As it turned out, I was wrong so I created this list to explain what I mean.
Goals And Interests In Project Development (aka Feature Factory):
The main stakeholder is the company paying for the features (called client further on), not the customer who is using them.
The responsibility for maintaining and evolving of the platform is not my job.
The requirements are defined by the client: I have no way to validate them because I have no contact with the users of the features. Feedback-based decisions are not possible.
Fast development but slow delivery.
Features are defined as a whole and delivered as a whole, not iteratively. Visual requirements (mock-ups) are un-negotiable because they are ordered as-is, even if the end user might not see it that way.
Perfection instead of usability.
Innovation is limited by restricted access to the infrastructure or other 3rd party services used by the client.
No involvement in long- and medium-term planning, as the goals of the client are not my goals. Very limited possibility to plan the architecture aligned with the strategy of the client.
The product my company sells is time and/or LoC. (Disclaimer: this would not be the case when working with Extreme Contracts)
The most important metrics are:
hours per week,
features per unit of time,
LoC
Goals And Interests In Product Development:
The main stakeholders are the end customers and the company itself (me and my team included).
The main goal is to identify users’ problems, develop solutions for them and solve them in the correct order. The job is no longer spending time with work or moving tasks on a Jira board, but to provide solutions.
Nowadays, with a large number of competitors who could appear every day, time-to-market (i.e. time) is decisive, but not at the expense of quality.
We own the maintenance and the evolution of the platform. It is our interest to produce high quality and robust software.
Through the cooperation of business analysts, UX experts, software developers and cloud experts, we are able to deliver features (capabilities) step by step, measure their benefits and decide on the next measures.
I can use all my skills and my company can benefit for them.
The user stories are written in a business-oriented manner, they can be taken literally. They document the proposed solution, can be cut into meaningful slices to be implemented quickly and reliably and to be delivered fast.
“Fail Fast” and “Inspect and Adapt” are the most important principles.
Usability, not perfection.
The most important metrics are:
customer satisfaction (measured with business metrics and the usage of delivered features),
In the first part I described why I think that continuous delivery is important for an adequate developer experience and in the second part I draw a rough picture about how we implemented it in a 5-teams big product development. Now it is time to discuss about the big impact – and the biggest benefits – regarding the development of the product itself.
Why do more and more companies, technical and non-technical people want to change towards an agile organisation? Maybe because the decision makers have understood that waterfall is rarely purposeful? There are a lot of motives – beside the rather wrong dumb one “because everybody else does this” – and I think there are two intertwined reasons for this: the speed at wich the digital world changes and the ever increasing complexity of the businesses we try to automate.
Companies/people have finally started to accept that they don’t know what their customer need. They have started to feel that the customer – also the market – has become more and more demanding regarding the quality of the solutions they get. This means that until Skynet is not born (sorry, I couldn’t resist 😁) we oftware developers, product owners, UX designers, etc. have to decide which solution would be the best to solve the problems in that specific business and we have to decide fast.
We have to deliver fast, get feedback fast, learn and adapt the consequences even faster. We have to do all this without down times, without breaking the existing features and – for most of us very important: without getting a heart attack every time we deploy to production.
IMHO These are the most important reasons why every product development team should invest in CI/CD.
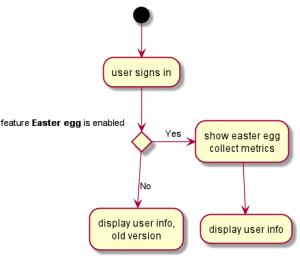
The last missing piece of the jigsaw which allows us to deliver the features fast (respectively continuously) without disturbing anybody and without losing the control how and when features are released is called feature toggle.
A feature toggle[1] (also feature switch, feature flag, feature flipper, conditional feature, etc.) is a technique in software development that attempts to provide an alternative to maintaining multiple source-code branches (known as feature branches), such that a feature can be tested even before it is completed and ready for release. Feature toggle is used to hide, enable or disable the feature during run time. For example, during the development process, a developer can enable the feature for testing and disable it for other users.[2]
Wikipedia
The concept is really simple: one feature should be hidden until somebody, something decides that it is allowed to be used.
function useNewFeature(featureId) {
const e = document.getElementById(featureId);
const feat = config.getFeature(featureId);
if(!feat.isEnabled)
e.style.display = 'none';
else
e.style.display = 'block';
}
As you see, implementing feature toggles is really that simple. To adopt this concept will need some effort though:
Strive for only one toggle (one if) per feature. At the beginning it will be hard or even impossible to achieve this but it is a very important to define this as a middle-term goal. Having only one toggle per feature means the code is highly decoupled and very good structured.
Place this (main) toggle at the entry point (a button, a new form, a new API endpoint) the first interaction point with the user (person or machine) and in disabled state it should hide this entry point.
The enabled state of the toggle should lead to new services (in micro service world), new arguments or to new functions, all of them implementing the behavior for feature.enabled == true. This will lead to code duplication: yes, this is totally ok. I look at it as a very careful refactoring without changing the initial code. Implementing a new feature should not break or eliminate existing features. The tests too (all kind of them) should be organized similarly: in different files, duplicated versions, implemented for each state.
the different states of the toggle lead to clearly separated paths
Through the toggle you gain real freedom to make mistakes or just the wrong feature. At the same time you can always enable the feature and show it the product owner or the stake holders. This means a feedback loop is reduced to minimum.
This freedom has a price of course: after the feature is implemented, the feedback is collected, the decision for enabling the feature was made, after all this the source code must be cleaned up: all code for feature.enabled == false must be removed. This is why it is so important to create the different paths so that the risk of introducing a bug is virtually zero. We want to reduce workload not increase it.
Toggles don’t have to be temporary, business toggles (i.e. some premium features or “maintenance mode”) can stay forever. It is important to define beforehand what kind of toggle will be needed because the business toggles will be always part of your source code. The default value for this kind of toggles should be false.
The default value for the temporary toggles should be true and it should be deactivated on production, activated during the development.
One advice regarding the tooling: start small, with a config map in kubernetes, a database table, a json file somewhere will suffice. Later on new requirements will appear, like notifying the client UI when a toggle changes or allowing the product owner to decide, when a feature will be enabled. That will be the moment to think about next steps but for the moment it is more important to adopt this workflow, adopt this mindset of discipline to keep the source code clean, learn the techniques how to organize the code basis and ENJOY HAVING THE CONTROL over the impact of deployments, feature decisions, stress!
That’s it, I shared all of my thoughts regarding this subject: your journey of delivering continuously can start or continued 😉) now.
p.s. It is time for the one sentence about feature branches: Feature toggles will never work with feature branches. Period. This means you have to decide: move to trunk based development or forget continuous development.
p.p.s. For the most languages exist feature toggle libraries, frameworks, even platforms, it is not necessary to write a new one. There are libraries for different complexities how the state can be calculated (like account state, persons, roles, time settings), just pick one.
Update:
As pointed out by Gergely on Twitter, on Martin Fowlers blog is a very good article describing extensively the different feature toggles and the power of this technique: Feature Toggles (aka Feature Flags)